In this blog post, I am going to make a bold prediction: that within ten years all major autonomous vehicle projects will join together in an open source consortium, tokenize the self-driving car project, and then quickly solve the self-driving car problem, making the traffic fatality rate close to 0 worldwide by 2030. And everyone who worked on the problem honestly will become massively wealthy and form the new world elite. And, of course, they’ll deserve it.
And faster than anyone has ever expected we will solve the problem of traffic fatalities: a problem kills 1.35 million people per year, (a number that makes the apparent 736190 covid-19 deaths pale in comparison).
I know this is a bold claim, and thus you should treat it with skepticism. Certainly this contention does not come without deep thought and analysis. I present an argument for your full consideration, deliberation, and criticism.
The goal is fewer deaths.
“The Big-Or Gate” Dilemma
For the argument, we consider a thought experiment. In this experiment, we consider the problem of self-driving cars in a low-speed environment (in say, a parking lot). In such an environment, the cars need some kind of “child detector” that triggers the car to stop when a child is detected within the path of the vehicle.
Here is the argument, which I will call “The Big-Or Gate Dilemma:”
- The best kind of “child detector” is one that has multiple detectors and if any one of them detects a child, the car should stop. I call this “The Big Or Gate” design. If detector one, OR detector 2, OR detector 3, OR detector 4, and so on, detect a child, the car should stop.
- These detectors may be implemented in many ways, with many different types of sensors, and many implementations may also include a “machine learning” component. Moreover, different solutions to this problem may be solved by different corporations, startups, and academics.
- Corporate culture induces a behaviour of secrecy, competitiveness, non-disclosure agreements, patent trolling, and an incentive to do better than the competition.
- Point 2 makes it so that it is very difficult for a consortium of hyper-competitive corporations to create a “big Or gate” design “child detector.”
- However, one may argue that on balance, a corporate structure is appropriate for designing self driving cars because of incentives. Open source projects don’t make money, one might say. It may be that the corporate structure is “the best we can do.” In other words, it might still be worth it to forego the idealistic but unrealistic notion of full cooperation, because we need to get it done and nobody is going to work for free.
- The Key Argument: Bitcoin, Ethereum, and Chainlink have now proven beyond all doubt that massive open source projects are possible and profitable. Through the use of tokenization these projects have already essentially created a functioning replacement of the banking systems, derivatives market, and insurance system. Moreover, those who have worked on these projects have seen massive and historic returns on their investments.
- Therefore: the key arguments for the competitive corporate structure falls apart. Open source projects have proven to be better, faster, and far more profitable than corporations. Therefore, the self driving car project should be tokenized, similar to how Bitcoin, Ethereum, and Chainlink have created open source projects to produce supply-controlled money, decentralized permissionless computers, and decentralized finance respectively.
- In addition to the above argument, an open source project also allows the public to audit the code. Given that we all share the road I think this alone is sufficient to legally require open-sourcing of the project. The fact that everyone working on it will become vastly more wealthy because of this is just icing on the cake.
- Finally: Because I believe tokenization of the self-driving car project is possible, safer, faster, and more profitable, doing this is also moral obligation and is inevitable. This is because across almost all major ethical systems, doing everything you can to protect the lives of children is universally considered to be the highest priority.
In future posts I will elaborate on the points made in this post. In particular, I will detail what I mean by a “tokenized open source project” and explain how this differs from a regular company or traditional consortium of companies. As well, in a future post I hope to discuss how a “self-driving car” token can be used as a kind of stake in insurance payouts when accidents occur. I will go through each point of “The Big-Or Gate Dilemma” in detail, analyze the game theory, and make the case.
I hope as well that it becomes clear that not only this will happen, but that it is indisputably one of the highest priorities of mankind.
Am I wrong? Is there a weakness to any part of the argument?
Please comment below if you think so.
 , meaning that the number of possible messages is on the order of
, meaning that the number of possible messages is on the order of 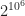 , vastly exceeding the number of atoms in the known Universe.
, vastly exceeding the number of atoms in the known Universe.